
Reflection 70B, sebuah trend "fake-claim" yang selalu berulang
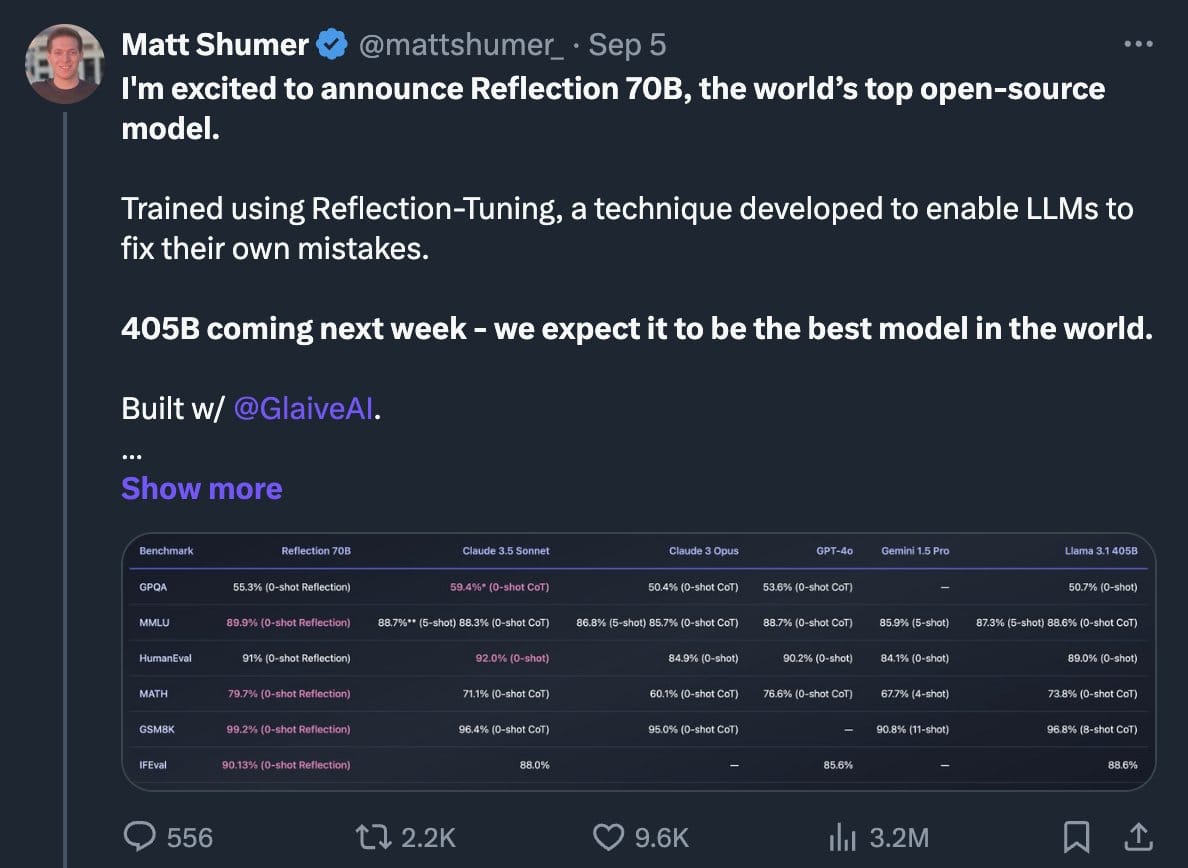
Beberapa hari belakangan, komunitas ML open-source dihebohkan dengan kehadiran model Reflection 70B. Sebuah finetuned model dari Llama3.1 70B yang diklaim mampu selevel dengan frontier model, sebut saja GPT-4o dan Claude 3.5 sonnet. Matt Shummer sebagai orang yang bertanggungjawab dibalik kehadiran model ini mengklaim modelnya di-finetune menggunakan teknik khusus yang disebut sebagai Reflection-tuning, yang pada dasarnya adalah menambahkan segmen <thinking></thinking> dan <reflection></reflection> secara eksplisit dalam format prompting LLM. Tujuannya agar LLM secara otomatis melakukan refleksi atas output yang telah ditulis.
You are a world-class AI system, capable of complex reasoning and reflection. Reason through the query inside <thinking> tags, and then provide your final response inside <output> tags. If you detect that you made a mistake in your reasoning at any point, correct yourself inside <reflection> tags.
(System prompt khusus yang dipakai oleh model Reflection 70B)
Dikarenakan klaim yang cukup bombastis, banyak pihak yang meragukan keabsahan model ini. Termasuk kami sendiri karena terdapat beberapa kejanggalan dan drama dalam perilisan Reflection 70B ini:
- Belum ada pihak independen yang berhasil mereproduksi hasil benchmark dari Reflection 70B.
- Analis independen, Artificial Analysis, melakukan testing dari open-weights yang diupload oleh pihak Matt Shummer pada tanggal 8 September 2024. Hasil dari evaluasi independen tersebut menunjukan model Reflection 70B TIDAK lebih baik dari Llama3.1 70B. Sumber


- Pihak Matt Shummer kemudian memberikan akses ke private endpoint Reflection 70B yang memberikan hasil yang cukup impresif, namun tidak adanya transparansi yang jelas model apa yang dijalankan dalam private API tersebut. Belum lagi versi open-weights modelnya yang hadir di HuggingFace hub yang sama sekali tidak mencerminkan klaim performa yang telah diujar pada awal perilisan.

- Berdasarkan hasil benchmark MMLU Pro yang dipublish oleh TIGER LAB dalam sebuah open benchmark. Reflection 70B mendapatkan skor yang bahkan lebih rendah dibandingkan vanilla weights dari Llama3.1 70B. Sumber

- Kami melakukan testing singkat terhadap Reflection 70B melalui endpoint publik yang tersedia di OpenRouter dan tidak menemukan bukti kuat bahwa model ini lebih baik dibandingkan vanilla Llama3.1 70 model.
Sejauh ini, belum ada bukti konkret dari klaim yang telah dilayangkan oleh pihak Matt Shummer terhadap kemampuan model ini. Kami menyarankan untuk tidak menyebarkan klaim baik ataupun buruk sebelum terkumpul cukup banyak bukti independen tentang model Reflection 70B dan teknik Reflection-tuning.
Tolok ukur dan sumber informasi yang paling absah menurut kami tetaplah open-weights yang sudah ataupun akan diupload oleh pihak Matt Shummer ke HuggingFace hub. Jika pihak Matt Shummer tidak mampu untuk menyediakan open-weights yang sesuai dengan klaim yang sudah bertebaran di banyak media dalam waktu dekat, maka aman dikatakan bahwa segala hype dan antusiasme yang sudah dibangun oleh perilisan Reflection 70B hanyalah teknik "fake-claim" yang selalu berulang dalam dunia teknologi.